It's still there! https://t.co/o5GvAzizfk Looks like there's a missing 's' in 'constraints' in your link, and looking at Google results, it seems the typo was originally mine at some point. I'll figure out how to make the old link work too.
Being a freelancer is an interesting role. You come across a variety of projects. I recently worked on a project involving replacing images in a PDF which taught me a couple of things.
While there are a number of tools to deal with PDF in Python, the general purpose tools can only do so much because… reason 2
PDF is a dump of instructions to put things in specific places. There is no logical way it is done that make general purposes tools manipulate the PDF in a consistent way.
Not everything is bad. Almost all positive changes like adding text or image and whole page changes like rotating, cropping are usually possible and so are all read operations like text, image extraction ..etc.,
The issue is when you want to delete something and replace it with something else.
With that learnt, I set out to achieve the goal anyway.
Step 1 – Understanding the format
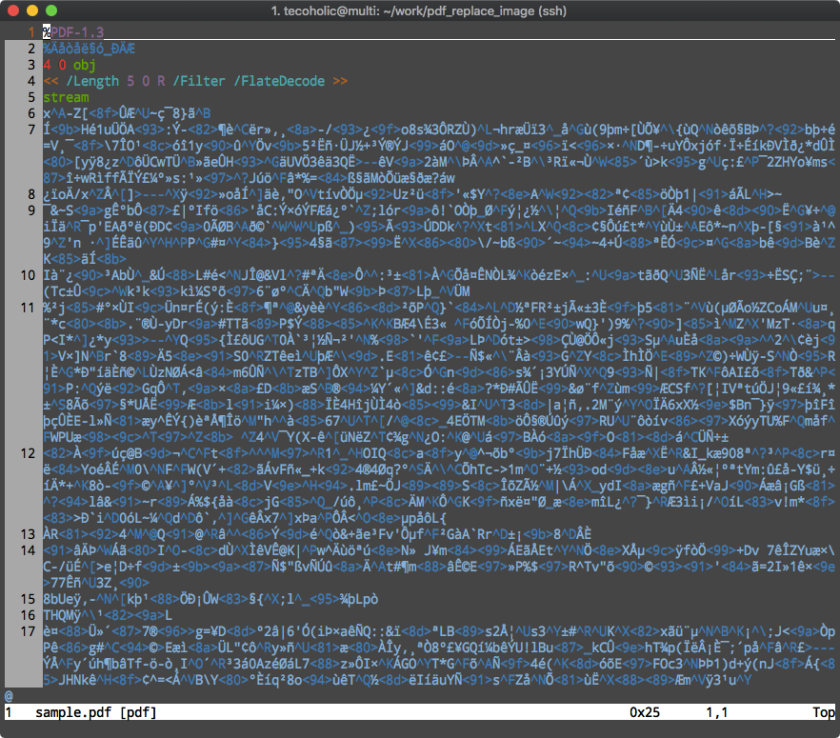
Humans invented the PDF format, which means they used words to describe things in the file, which means we can read them. So opening a PDF file in a text editor like VIM will show something like this.
Without getting into the entirety of the PDF spec, let us see what this means. PDF is a collection of objects. There is usually an identifier like int int obj followed by some metadata and then a stream of binary information starting with stream and ends with endstream and endobj. A image in our case would be represented as
16 0 obj
<< /Length 17 0 R /Type /XObject /Subtype /Image /Width 242 /Height 291 /Interpolate
true /ColorSpace 7 0 R /Intent /Perceptual /BitsPerComponent 8 /Filter /DCTDecode
>>
stream
Image binary data here like ÿØÿá^@VExif^@^@MM^@*^@^@^@^H^@^D^A^Z^@^E^@^@
endstream
endobj
So to successfully replace an image we will have to replace the image binary data and the metadata like width and height.
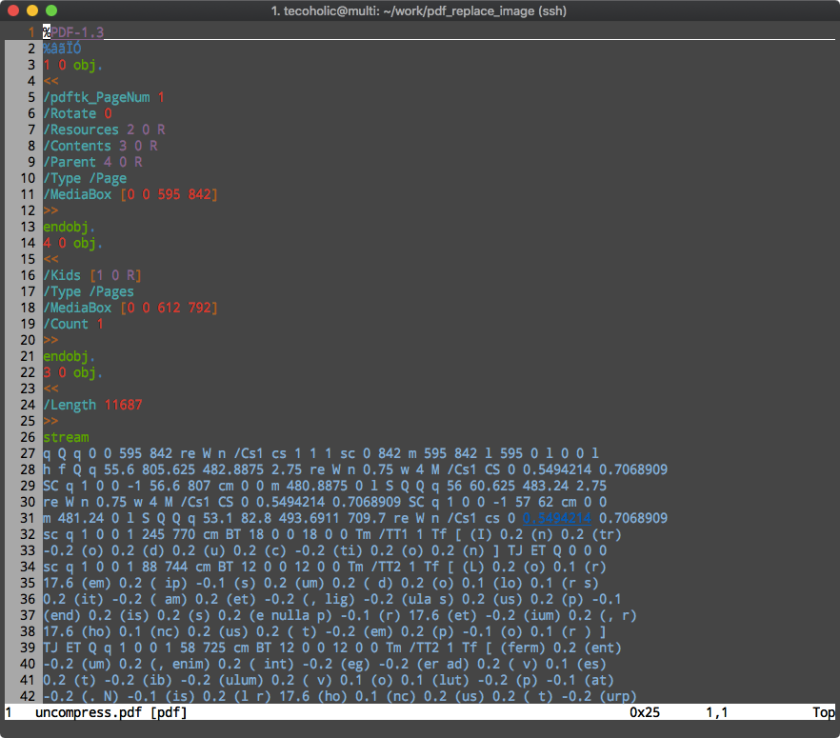
Step 2 – Uncompressing the PDF and extracting the images
Use a PDF manipulation called toolkit called PDFtk.
What this command does is, it uncompresses the file and makes it easier to read and manipulate. Let us open the uncompressed.pdf in VIM to see the difference.
Step 3 – Identifying the image to replace
PDF is essentially a collection of objects and a PDF file might contain multiple images, there is no way to identify a particular image in the binary data of the PDF file (unless you are from Matrix). We will have to first extract the images from the PDF and match the PDF object to the image using its metadata like height and width. To do that install pdfimages command-line tool (part of poppler-utils) and run pdfimages -list uncompressed.pdf. This will list all the images in the PDF with their metadata.
Next extract all the images in their original formats using
pdfimages -all uncompressed.pdf image
That extracts the files and names them after the prefix we provided like this image-000.jpg image-001.jpg image-002.jpg.
Now open your images check their file’s height, width and file size and mark the details for the one to replace. In my case the file details were:
height – 185
width – 277
size – 70836
There are two images which matches the height and width, thankfully they have different file sizes.
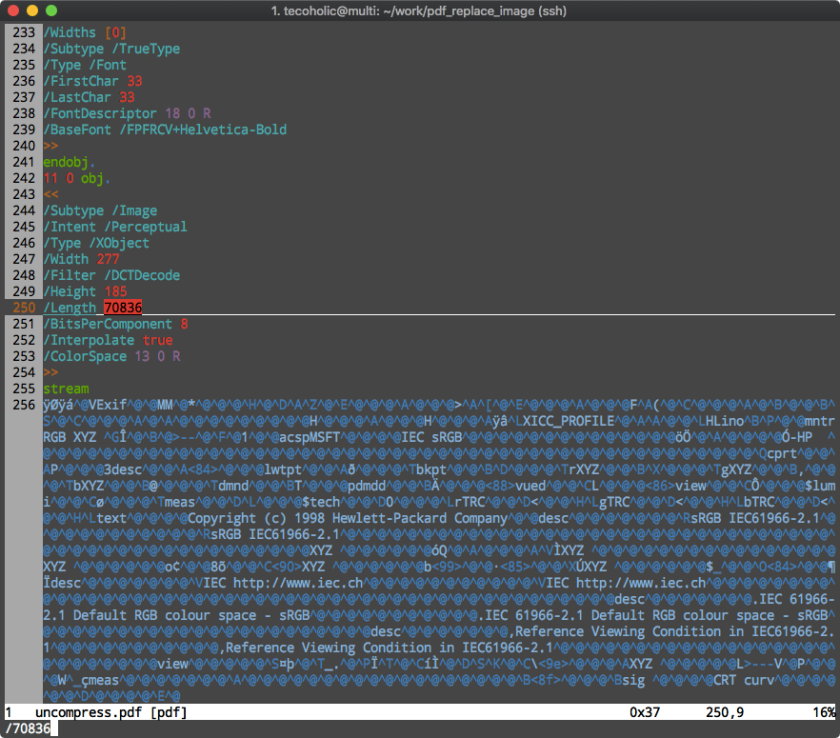
Step 4 – Identifying the object in PDF that represents the image
I opened the uncompressed.pdf in VIM and searched for the most unique value I have found for the image – its size.
Now we can identify the object identifier, in this case it is 11 0 obj.
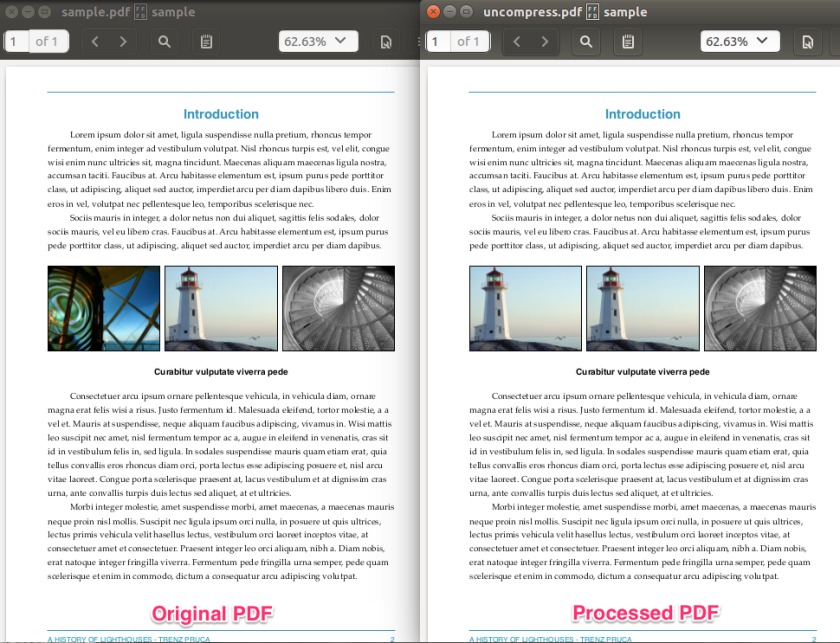
Step 5 – Replacing the image with another image
Now the job is to switch the object 11’s image data with our image’s data. You can use the following Python script to achieve that.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
As a freelancer one of the things that comes with getting a project/job is handling technical interviews. I have so far managed to convince the client with a work sample, test project …etc., This is literally the first time I sat for a full technical interview. And it did teach a few lessons. Let me document it for future use.
It started off with the basic of the language:
1. What is the difference between an iterable and an iterator?
3. Can you tell me some advantages of Python over other languages?
I rambled something like, it is is easier to read and write. The file structure (I should have said modules/packages) is great. Even modern iterations of Javascript are copying the importfrom syntax. Native implementation of a lot of things in standard library…etc.,et.,
But the thing my interviewer was looking for were the words “automatic garbage collection” because the next question was
4. How does Python handle memory?
Python has automated memory management and garbage collection.That is why we never worry about how much memory we are allocating like C’s malloc `calloc functions.
5. Do you know how Python does that? Do you know about GIL?
sheepish smiles and saying no’s ensued. I ran into an issue a few months back, I think maybe with a DB connection issue or something which led me on a rabbit hole that ended with GIL. I should have learnt it that day.
8. How does the browser know where your server is when the information is submitted to a particular URL?
DNS servers – IP resolution
9. The server sends back text as a string how do you see colorful information in browser?
The text is converted into DOM elements which are rendered by the browsers rendering engine.
10. If a browser is showing unreadable character and question marks instead of displaying the information what could be the reason?
Document Encoding mismatch. The server might send the data encoded in Unicode UTF-8 and the browser might be decoding it as ASCII or LATIN-1 resulting in weird characters and question marks being rendered in the browser.
11. You said Unicode and UTF-8 what is the difference?
Unicode is the term used to describe the character set. If it is encoded with 8 bits it is called UTF-8, if encoded with 16 bits it is called UTF-16 etc.,
Some other questions, that were asked:
1. Do you know Docker? Have you used AWS?
2. Do you know Data Base schema design?
3. You have a SQL query that takes a long time to execute. How would you begin to make it faster? Do you know about Query optimisation and execution plans?
Yesterday, I was working on the ward level parks map of Chennai I had to join a CSV data layer with the boundary polygon layer, but there was one issue while my CSV file has the ward numbers as integers (1,2,3..etc), the polygon layer had them as strings (Ward 1, Ward 2, Ward 3 …etc.,) So I was thinking, wouldn’t it be nice just to strip the word Ward and put it in a new column, so that I can make a join by matching the ward numbers. Turns out Python integration in QGIS is so good that, I did it without even searching the internet. Here is how.
Open the Attribute table
Open Field Calculator.
Enter the “Output field name”
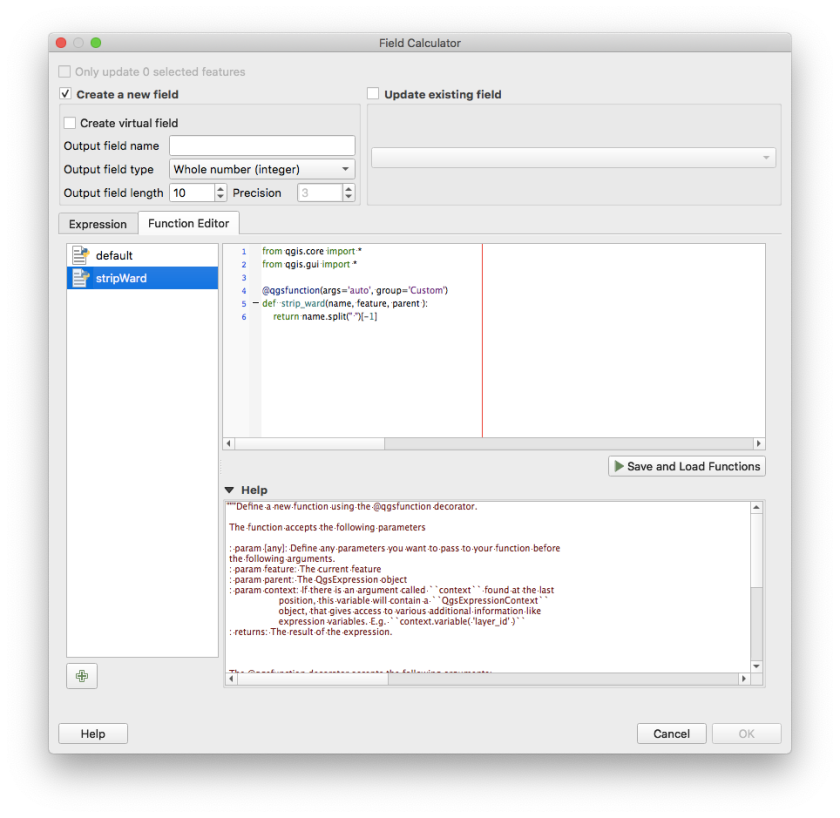
Switch to “Function Editor”
Click the [+] button to create a new function file.
Changed the function name, parameter and return the value after stripping “Ward ” from the string. Read the docs given below the function editor to understand what’s going on the file.
QGIS Field Calculator
from qgis.core import *
from qgis.gui import *
@qgsfunction(args='auto', group='Custom')
def strip_ward(name, feature, parent ):
return name.split(" ")[-1]
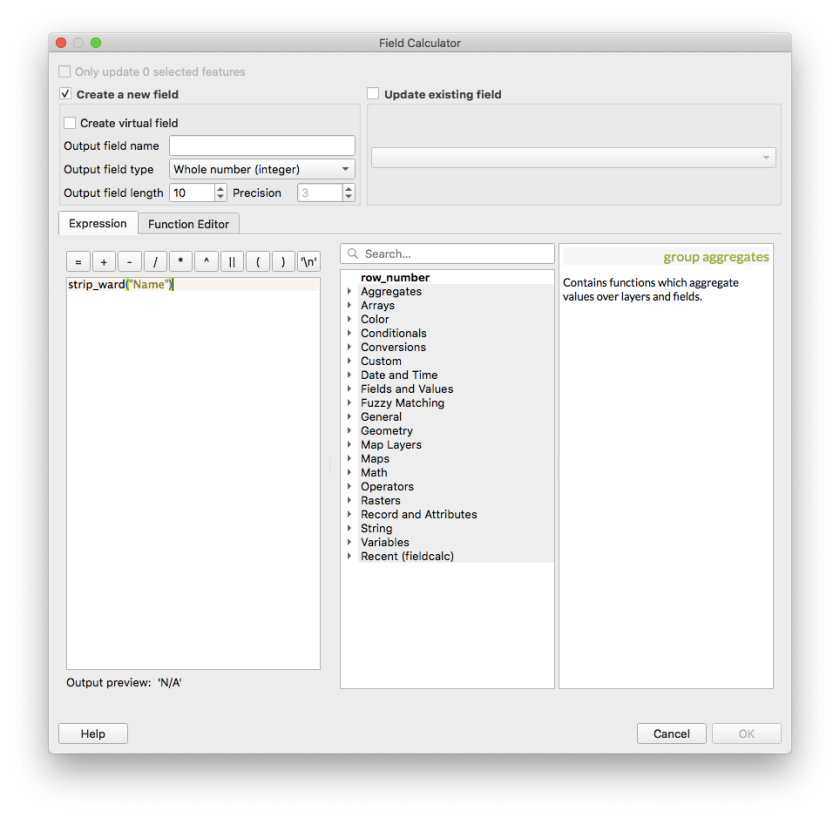
Now switch back to the Expression tab and call the function to calculate the new field
Click OK. Now the new field with the computed value would be created.
I had a simple use case, by one can use the power of Python to calculate anything from existing data and generate a new field based on it. I was really blown away by the level of Python integration in QGIS.
In situations where you have a list of objects and have to retrieve then in random order, dictionaries can act as lookup tables.
users = list of class User
# Get users one by one by looking up ids
user_1 = next((u for u in users if u.id == user_1_id), None)
user_2 = next((u for u in users if u.id == user_2_id), None)
...
# Simpler solution using lookup table
lookup = dict((u.id, user) for u in users)
user_1 = lookup[user_1_id]
user_2 = lookup[user_2_id]
...
This tip is not very obvious, hence this explanation:
user_1 = next((u for u in users if u.id == user_1_id), None)
This method employs a iterator looping through the list of users every time we have to find a user, which means we have to run this loop a hundred times. This poses a complexity of O(N2).
lookup = dict((u.id, user) for u in users)
user_1 = lookup[user_1_id]
This method on the other hand iterates through the users list one time and create a lookup table that we can again and again without having to iterate through the list every time. This reduces the complexity to O(N) which could theoretically lead up to 10 times faster execution of the program.
Sometimes we have to deal with external objects and their attributes. getattr() can save you at those times.
# Get the attribute name
name = obj.name # AttributeError if name is not present
# Check if the attribute is present before fetching
try:
name = obj.name
except AttributeError:
name = "Guest"
# Simpler solution
name = obj.name if hasattr(obj, "name") else "Guest"
# Simplest Solution
name = getattr(obj, "name", "Guest")
Check for existence of a key in dictionary and retrieve its value if present.
dictionary = { "key": "value" }
# checking for the presence and key and getting the value
wanted = None
if "key" in dictionary:
wanted = dictionary["key"]
# Simpler version
wanted = dictionary.get("key", None)

{kind=link}