OpenZim is a Wikimedia developed format for offline reading of Wikipedia. Read more here. But the project was sadly sidelined and the support from MediaWiki, the software that runs Wikipedia sites, was also removed.
I came to know about all this from Bala Jeyaraman of Vasippu. He is planning to introduce tablets in a classroom of 6th standard students, with exceptional comprehension levels compared to average Indian classrooms, and wanted a way to load select material into the tablets. The OpenZim files have an excellent reading app called Kiwix, which also offers complete Wiki sites as downloads. Tablets can’t afford to have a huge amount of data, like full Wikipedia. There is no way to create a zim file with select topics. One has to request the OpenZim team to do it for him/her.
Enter Zimbalaka
Zimbalaka is a project which tries to solve just that. It creates offline wikipedia content files in zim file format. A person can input a list of pages that need to be created as a zim, or at least a Wikipedia category. Then Zimbalaka downloads those pages, removes all the clutter like sidebar, toolbox, edit links …etc., and gives a cleaned version as a zim file for download. It can be opened in Kiwix.
The zim is created with a simple welcome page with all the pages as a list of links. The openzim format also has an inbuilt search index and Kiwix uses this really well. So you can create zims of 100 articles and still navigate to them easily either way.
Zimbalaka has multi-lingual and multi-site support. That is, you can create a zim file from pages of any language of the 280+ existing Wikipedias, and also from sites like Wikibooks, Wiktionary, Wikiversity and such. You can even input any custom URL like (http://sub.domain.com/), Zimblaka would add (/wiki/Page_title) to it and download the pages.
It is currently hosted by my good friend Srikanth (@logic) at http://srik.me/zimbalaka
Screenshots
Here is how the content looks in Kiwix for Android.
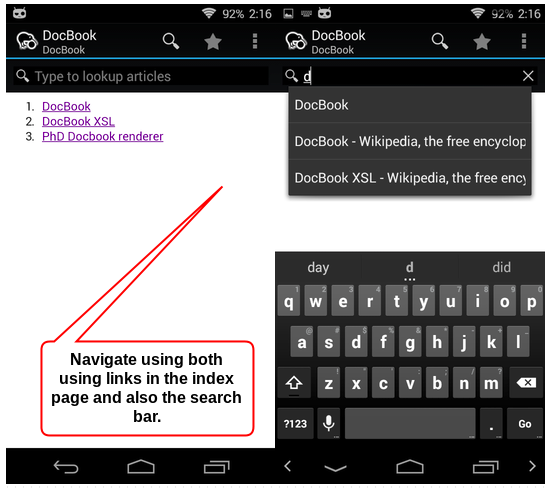
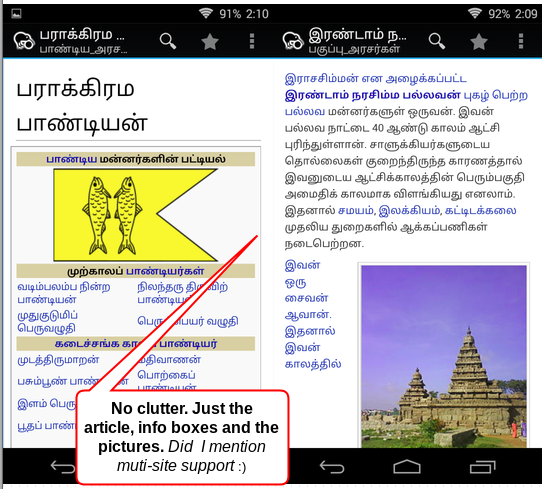
Pain points
- A small pain point is that Zimbalaka also strips the external references that occur at the end of the Wikipedia articles, as I didn’t find it useful in an offline setup.
- You cannot add a custom Welcome page in the zim file. Not a very big priority. The current file does its work of listing all the pages
- You cannot include pages from multiple sites as a single zim file. The workaround is to create multiple files or use a tool called zimwriterfs, which has to be compiled from source (this is used by zimbalaka behind the scenes).
Developers
This tool is written using Flask – A simple Python web framework for the backend, Bootstrap as the frontend and uses the zimwriterfs compiled binary as the workhorse. The zimming tasks are run by Celery, which has been automated by supervisord. All the coordination and message passing happen via Redis.
Do you want to peek in how it is all done? Here is the source code [https://github.com/tecoholic/Zimbalaka]. Feel free to fork, modify and host your own instance.
Update
The OpenZim team has appreciated the effort I had put in and offered to host the tool on their server at http://zimbalaka.openzim.org. They have also pointed me to the desired backend called ‘mwoffliner’ that they have developed to download and clean the HTML. I will be working on it in my free time.