NER Annotator is now available to use directly from the browser
https://tecoholic.github.io/ner-annotator/
Background
As with most things, this started with a problem. Dr. K. Mathan is an Epidemiologist tracking Covid-19. He wanted to automated extraction of details from government bulletins for data collection. It was a tedious manual process of reading the bulletins and entering the data by hand. Since the bulletins has paragraphs of text with text in them, I was looking to see if I can leverage any NLP (Natural Language Processing) tools to automate parts of it.
Named Entity Recognition
The search led to the discovery of Named Entity Recognition (NER) using spaCy and the simplicity of code required to tag the information and automate the extraction. It kind of blew away my worries of doing Parts of Speech (POS) tagging and then custom writing an extraction algorithm. So, copied some text from Tamil Nadu Government Covid Bulletins and set out test out the effectiveness of the solution. It worked pretty well for the small amount of training data (3 lines) vs extracted data (26 lines).
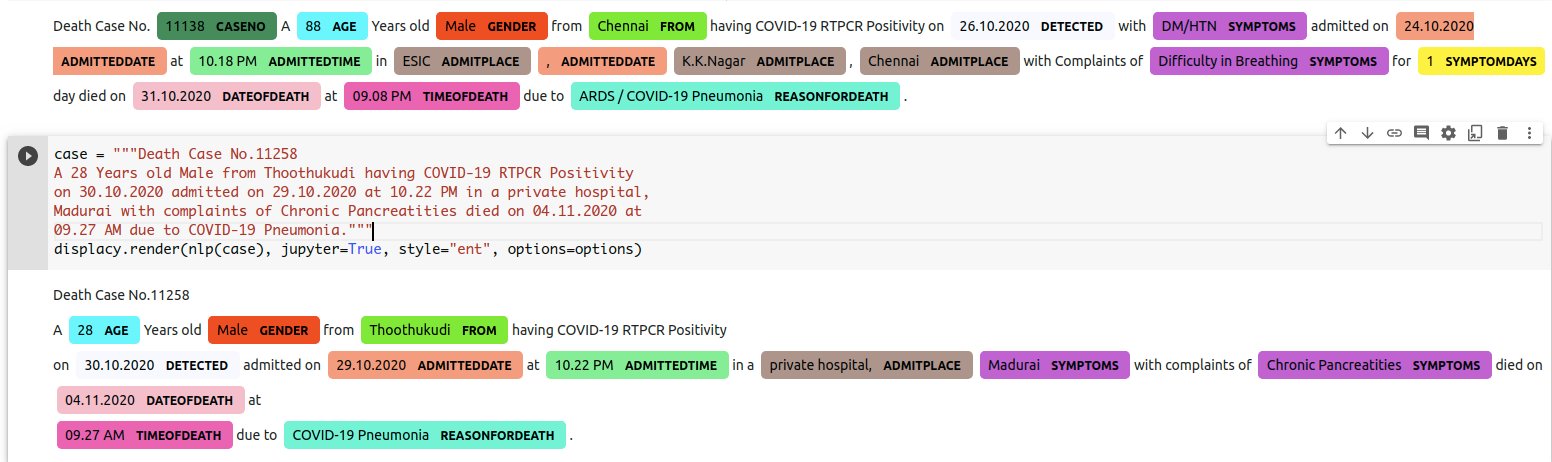
Trying out NER based extraction in Google Colab Notebook using spaCy
But it had one serious issue. Generating Training Data. Generating training data for NER Annotation is a pain. It is infact the most difficult task in the entire process. The library is so simple and friendly to use, it is generating the training data that is difficult.
Creating NER Annotator
NER Annotation is fairly a common use case and there are multiple tagging software available for that purpose. But the problem is they are either paid, too complex to setup, requires you to create an account or signup, and sometimes doesn’t generate the output in spaCy’s format. The one that seemed dead simple was Manivannan Murugavel’s spacy-ner-annotator. That’s what I used for generating test data for the above example. But it is kind of buggy, the indices were out of place and I had to manually change a number of them before I could successfully use it.
After a painfully long weekend, I decided, it is time to just build one of my own. Manivannan’s tagger just uses JavaScript to create the training data JSON and then requires a conversion using a Python Script before it can be used. I decided to make it a little more bug proof.
This version of NER Annotator would:
- Use a Python backend to tokenize and detokenize text for tagging and generating training data.
- The UI will let me select tokens (idea copied from Prodigy from the spaCy team), so I don’t have to be pixel perfect in my selections.
- Generate JSON which can be directly loaded instead of having to post-process it with Python script.
The Project
I created the NER with the above goals as a Free and Open Source project and released it under MIT License.
Github Link: https://github.com/tecoholic/ner-annotator
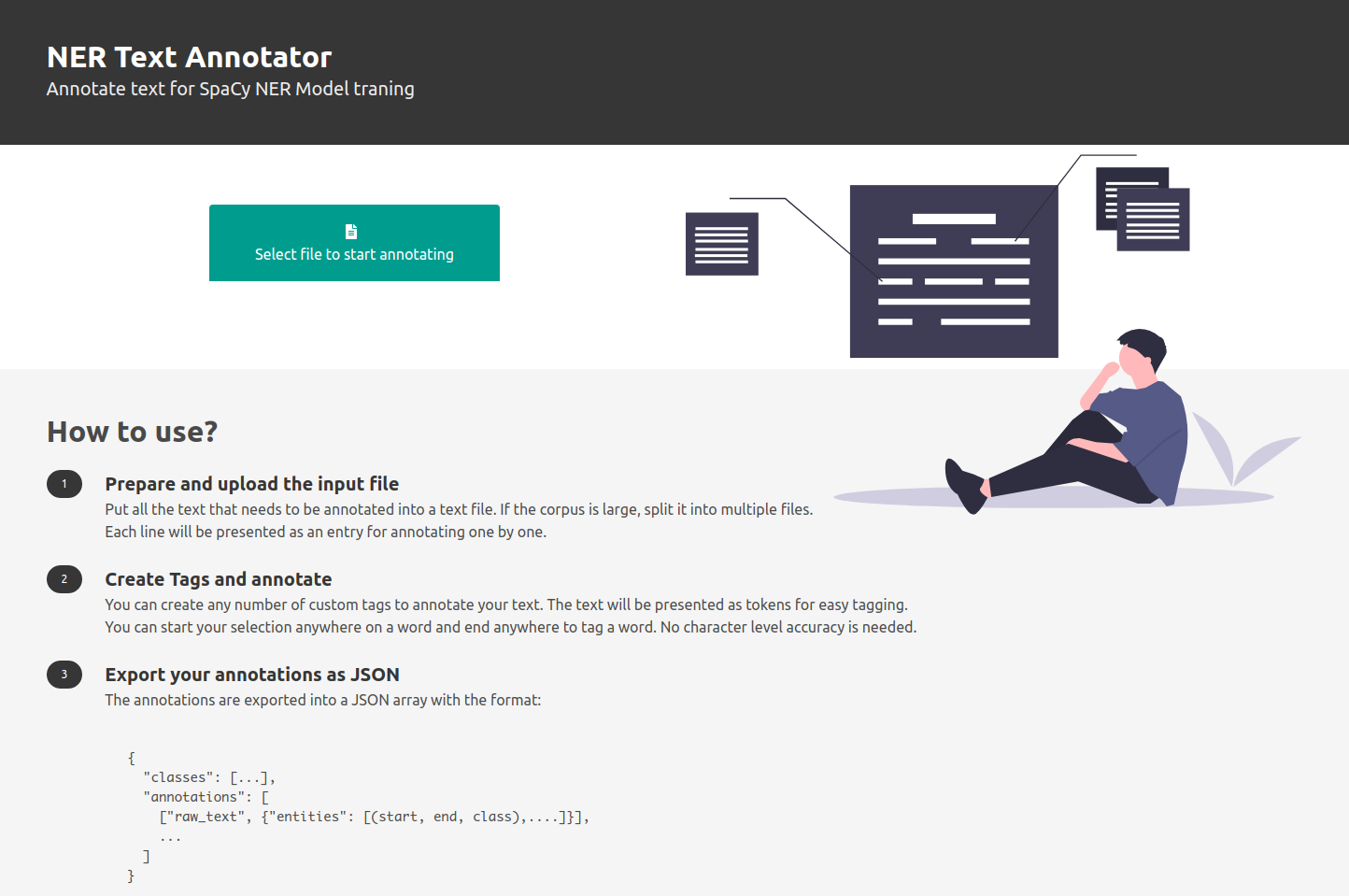
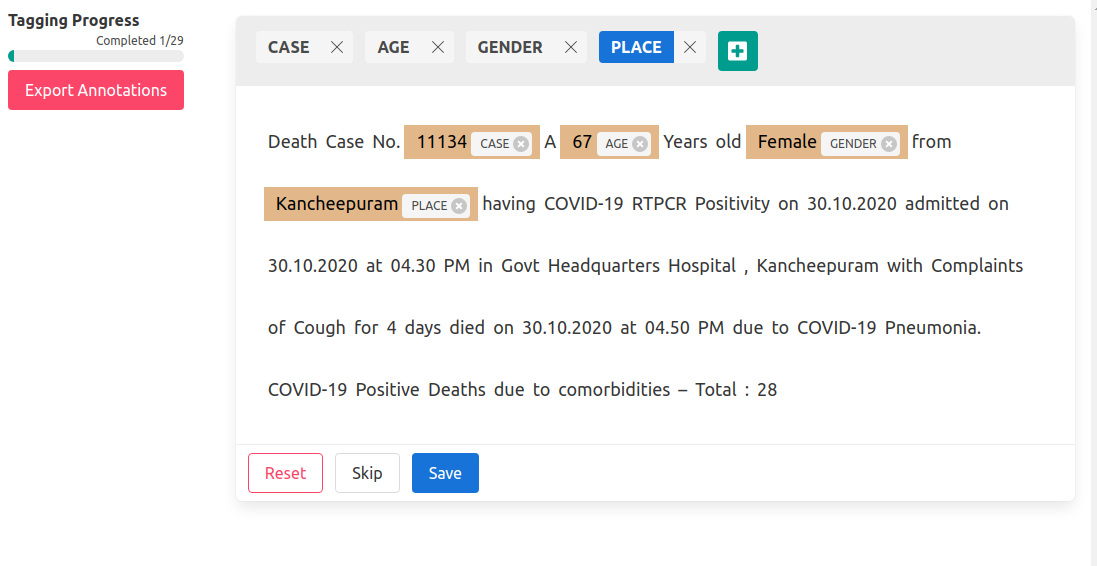
Credits
Thanks to Philip Vollet noticing it and sharing it on LinkedIn and Twitter, the project has gotten about 107 stars on Github and 14 forks, which is much more reach than I hoped for.
Thanks to @1littlecoder for making a YouTube video of the tool and showing the full process of tagging some text, training data and performing extractions.