I have run into this issue multiple times with Nomad. For some reason, when jobs are redeployed/restarted, the service registration isn’t removed. This causes my Traefik reverse proxy to send requests to a non-existing allocation in Nomad.
Last time this happened, I think I completely nuked the Nomad setup and setup everything from scratch. This time around, I finally figured out the right way to do things.
Use nomad service list to get a list of the services
The use nomad service info -verbose <service_name> to get the service registrations for the app having the issue.
Open the UI and click on the Job > Services and click on the allocations to identify the dead allocation
Note the allocation ID and get the corresponding ID from the service info
Finally, remove the ghost entry with nomad service delete <service-name> <ID>
Change the Policy of the role applied to the user. Since I have a single person instance, I just needed to update the default Policy Template from the Control Panel
Go to Control Panel
Click Roles
Either change the “Role Template” if you have no roles defined, or edit the role governing the users for whom the limit needs to be changed.
4. Their “Roles” page should show the new limit under driveCapacityMb and also their “Drive” page in Basic Settings
Getting Pyenv and Pyright to play nice in python-mode on Doom Emacs requires sticking to a few rules. I discovered these after multiple attempts of trial and error. All the following things might not be needed. But I got things to work only when I set all of these up.
So, best advice is – start here and try to reduce it down.
Emacs Config
Edit your .doom.d/init.el
Enable both lsp and tree-sitter in the tools. tree-sitter is not probably needed for this. But, I wanted to use it, so.
Enable python mode with (python +lsp + tree-sitter +pyenv +pyright)
Then run ~/.emacs.d/bin/doom sync and then ~/.emacs.d/bin/doctor to ensure the required tools are available.
Setting up your Python Env
Add your project as a Projectile project using SPC p a
Now if you have read the Projectile script you would have noticed that the “pyenv mode” sets the name of the project as the Python environment name. So, if you like me use pyenv-virtualenv to create multiple virtual environments, then create your virtualenv with the same name as your project and install the dependencies within that virtualenv. For example,
# project name is awesome-sauce
cd awesome-sauce
pyenv virtualenv 3.11 awesome-sauce
pyenv local awesome-sauce
pip install -r requirements.txt # or any way you want to setup the dependencies
This will create a local .python-version file with the virtualenv name. This file seems to be crucial in getting the pyright to work. I tried multiple times without this file and just using pyenv shell <env> to activate the env and install the dependencies. And when I loaded up a file in Emacs, pyright would complain that none of the dependencies were available for import.
Results
With all of this setup clearly, now I get autocompletion for dependencies installed via pip as expected, and syntax checking is happening as I type.
Notice that in the modeline, pyenv has loaded the correct environment and the LSP is also using the same one (the blue Python awesome-sauce).
I can now also run my tests quickly using SPC m t t using pytest.
Finally – a request
There’s a big chance that I might have missed something while documenting this. In case you are trying to achieve the same setup, but these rules aren’t sufficient to get things working for you, kindly drop a line.
Let’s say you set up Doom Emacs from scratch for the first time, and you followed the instructions correctly and install the all-the-icons fonts when prompted, saw the icons properly displayed in the dashboard (launch window), but once you open a file, the status line starts showing random characters, instead of icons.
You need to install nerd-icons using M-x nerd-icons-install-fonts because the doom-modline has switched from all-the-icons to nerd-icons
Everyday I work on a megalith of a software called Open edX as a part of my work. It is built on top of Django. But here is the thing, it is very big piece of software and most of time I am tweaking something that is one among the many layers of abstraction and business logic.
This has created a deep desire to get down to the basics and build something. I tried learning Rust. A systems language. How more basic can I get than that? But what do I do with Rust? I don’t even know what kind of program I can write with that. A PDF Parser maybe? I downloaded the PDF 1.7 spec and started gathering 8 bits at a time. But Rust is not something that has the same velocity as Python or JavaScript. Understandably so. Compiled vs Interpreted.
In the meantime, something has also been really bothering me. My personal finance. Every year, I do a round up of my earnings and spends during the tax season and go over my savings. This year around, I have setup Firefly III to consume my bank statement and do it a little easier.
FireFly III is a fantastic software that made me realise a number of things I didn’t know about my finances
But…
I needed more. I have tasted something sweet and I need more. Here are the things I wanted Firefly to have to make life easier for me
Native support for importing my bank statement. The Firefly Importer does its job, but I needed run an extra service for that and had to create a template for mapping the fields.
Native support for importing PDF Credit Card statements. A lot of the details are being missed because all the expenses for a month are reported as a single entry in the bank statement – CC Payment.
Automatic Categorisation of transactions. Firefly let us to set up static rules that can help do this, but I found it a little complex and I was always afraid one rule might override another and my categorisation would go for a toss.
So…
Why don’t I create a simple personal finance application in Python Django? I know the language and the framework. Creating something like this from scratch would allow me to get to the basics of Django. Get back to working with HTTP Responses, redirects, URL resolution, Middleware, Testing…etc., I use TDD and take help from ChatGPT to get the skeleton code.
I have also grown tired of the modern frontend development, the complexity is too much. This has helped me reset. Writing HTML in Django templates has been very cathartic. When I do need some interactivity, I plan on using HTMX. No Webpack, No bundling, None of the 1000 things that come with it.
I know, this doesn’t sound as sexy as “written in Rust”. But, working on this project has been very satisfying. It allows me to revisit things that I haven’t used in a long time. Build something I really want to use. And most importantly, takes me back to the basics – well at least to the basics of the abstraction layer Django provides.
The Project
The Project is named “En Kanakku” (என் கணக்கு) which is Tamil for “My Accounts”. Over the last couple of weeks, I have implemented:
Setup the dependencies and the basic skeleton for the app
Created a CSV Importer that can be subclassed to import transactions from any CSV file
Used it to create an importer for the Firefly III export
Added an admin action to merge account after the import
Now all of the transaction data I had in Firefly has been imported into En Kanakku, along with the accounts and categories. Baby steps…
and this post is about how I use Nomad to deploy software.
But before that…
I have some updates in the networking department. I had mentioned in Part 2 that, I use Nginx as a reverse proxy to route traffic from the internet into my public apps like Misskey.
By picking up the cues from Nemo’s setup, I experimented with Traefik and replace Nginx with Traefik. It was made easier by the fact that Traefik fully supports Nomad service discovery. That means, I don’t have to run something like Consul just to handle the service to Traefik Proxy mapping.
Running Traefik
I was running Nginx as a Systemd service in the OCI virtual machine and Nomad was limited to running services in my Intel NUC. While moving to Traefik, I configured the OCI VM as a Nomad client and attached it to the Nomad “Cluster”. Since Nomad is running on the Tailscale network, I didn’t have to fiddle with any of the networking/firewall stuff in the OCI VM, making the setup simple.
Traefik is run as a Docker container in the VM with the “host” network mode so that it listens to the VM ports 80/443, which are open to the outside internet. I have specifically mapped the Traefik dashboard to the “tailscale” network, allowing me to access the dashboard via SSH tunneling without have to have the 8080 port open to the rest of the world.
All the services are written as Nomad Job specifications, with a specific network config, and service definition. Then I deploy the software from my laptop to my homeserver by running Terraform.
Ideally, I should be creating the Oracle VM using Terraform as well. But the entire journey has been a series of trail and error experiments, that I haven’t done that. I think I will migrate to a Terrform defined/created VM once I figure out how to get Nomad installed and setup without manually SSHing into the VM.
Typical Setup Workflow
Since, most of what we are dealing with are web services, I haven’t run into a situation where I had to deal with a non-docker deployment yet. But I rest easy knowing that when the day comes, I can rely on the “exec” and “raw_exec” drivers of Nomad to run them using pretty much the same workflow.
Dealing with Secrets
One of the biggest concerns about all of this is dealing with secrets like, DB credentials, API Keys, ..etc., For example, how do I supply the DB Username and Password to the Nomad Job running my application without storing them in the Job configuration files which I have on version control?
There are many ways to do it, from defining them as Terraform variables and storing it as git-ignored file withing the repo to deploying Hashicorp Vault and using the Vault – Nomad integration (which I tried and found to be an overkill).
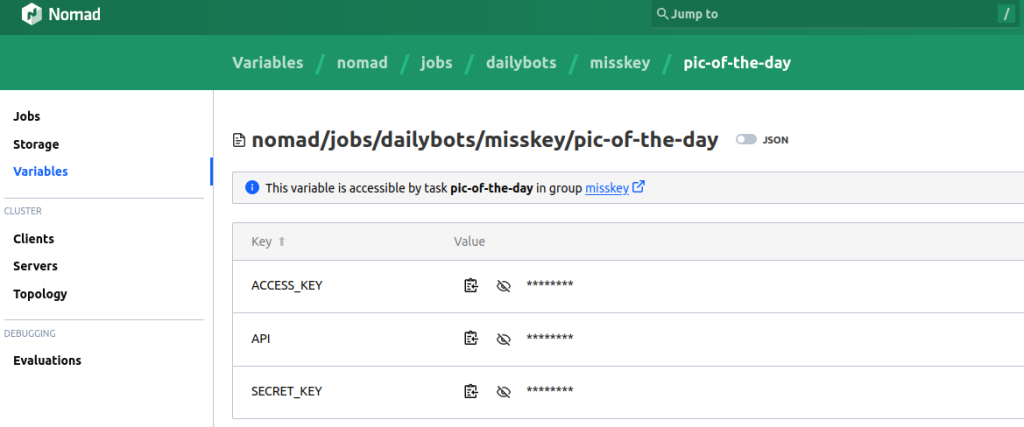
I have chosen the simpler solution of storing them as Nomad Variables. I create them by hand using the Nomad UI, and they are defined with specific task access.
An example set of secrets
These are then injected into the service’s container as environment variables using the template block with nomadVars.
// Nomad config for getting secrets from Nomad Variables
template {
data = <<EOH
{{ with nomadVar "nomad/jobs/owncloud/owncloud/owncloud" }}
OWNCLOUD_DB_NAME={{.db_name}}
OWNCLOUD_DB_USERNAME={{.db_username}}
OWNCLOUD_DB_PASSWORD={{.db_password}}
OWNCLOUD_ADMIN_USERNAME={{.admin_username}}
OWNCLOUD_ADMIN_PASSWORD={{.admin_password}}
{{ end }}
{{ range nomadService "db" }}
OWNCLOUD_DB_HOST={{.Address}}
{{ end }}
{{ range nomadService "redis" }}
OWNCLOUD_REDIS_HOST={{.Address}}
{{ end }}
EOH
env = true
destination = "local/env"
}
Accessing Private Services
While this entire project began with trying to self host a Misskey instance as my personal Mastodon alternate, I have started using the setup to run some private services as well – like Node RED, that runs automation like my RSS-to-ActivityPub bots.
I don’t expose these to the internet, or even the Tailscale network at the moment. They are run on my home local network on a dynamic port assigned to by Nomad. I just access it through the IP:PORT generated by Nomad.
Node-RED running at local IP and Dynamic (random) port
I will probably migrate these to the Tailscale Network, if I start traveling and would still want to have access to them. But for now, they are just restricted to my home network.
Conclusion
It has been a wonderful journey figuring all of this out over the last couple of weeks and running the home-server has been a great source of satisfaction . With Docker and Nomad, it has been really easy to try out new services, and set them up quickly.
I woke up on a Sunday and wanted to setup Pihole for blocking ads. I had the house running via Pi-hole in 30 mins. I have found a new kind freedom with this setup. I see this as a small digital balcony garden on the internet.
In part 1, I wrote about the hardware, operating system and the software deployment method and tools used in my home server. In this one, I am going to cover one topic that I am least experienced in – Networking
Problem: Exposing the server to the internet
At the heart of it, this the only thing in Networking I really wanted to achieve. Ideally the following is all I should have needed:
Login to my router
Make the IP of my Intel NUC static, so that DHCP doesn’t assign a different value every time it reboots
Setup port forwarding for 80 (HTTP) and 443 (HTTPS) in the router to the NUC.
Use something like DuckDNS to update my domain records to point to my public address.
I did the first 3 steps, and tried to hit my IP. Nothing. After some searching on the internet, I came to realize that my ISP doesn’t provide Public IPs for home connections anymore and my router is under some NAT (don’t know what it is).
Before I outline how everything is setup, I want to highlight 2 people and their self-hosting related blogs:
All the devices that I install Tailscale in and login becomes a part of my private network.
I added my Intel NUC and the Oracle VM to the Tailscale network and added the public IP of the Oracle VM to the DNS records of my domain.
Now requests to my domain go to the OCI VM, which then get forwarded to my NUC via the Tailscale network.
Some Tips
Tailscale has something called MagicDNS which once turned on allows accessing the devices using their name instead of their IPs. This allows configuring things quite easy.
Oracle VM’s by default have all of their Ports Blocked except for 22 (SSH). So after installing the webserver like Nginx or Apache, 2 things need to be done:
Add Ingress Rules allowing traffic to ports 80 and 443 for the Virtual Cloud network that the VM is configured with
Configure the firewall to open the ports 80 and 443 (ufw allow <port>)
I think there are many ways to forward the requests from one machine to another (OCI Instance to Homeserver in this case). I have currently settled for the most familiar one – using Nginx as Reverse Proxy.
There are 2 types of applications I plan to host:
Public applications like Misskey which are going to be accessed by anyone who wants to.
Private applications like Node-RED which I am going to access 99.99% from my laptop connected to my home-network.
I deploy my public applications to the Tailscale Network IP in my homer server and make them listed to a specific port. Then, in the Nginx reverse-proxy configuration on the OCI VM, I set the proxy_pass to something like http://intel-nuc:<app-port>. Since I am using Tailscale’s magic DNS, I don’t have to hard-code IP values here.
For Private applications, I simply run them on the Intel NUC’s default local network, which is my router and other things connected to it (including my laptop) and access it locally.
Up next…
Now that the connectivity is sorted out, the next part is deploying the actual application and related services. I use Nomad to do that. In the next post I will share my “architecture” and how I use Nomad and Terraform to do deployments and some tricks I learnt using them.
I had an old Intel NUC lying around that I always wanted to put it to good use. I had set it up as a home media server using Plex a couple years back, but streaming services and the newer content coupled with 100-300Mbps Fiber Internet connections have kind of made it redundant.
So, when finally a couple of weeks back when I wanted to switch from Twitter to Mastodon, I got the idea to just host an instance for myself. But Mastodon was in Ruby and I was at the time reading through the ActivityPub Protocol specifications to see if I can create an account using just a couple of scripts and a bunch of JSON files. I didn’t get far in the experiment, but someone ended up finding out Misskey. I setup a Misskey instance on Digital Ocean and set out to preparing the NUC for a home-server.
Hardware
The NUC I have has a Intel i3 processor with 4 cores each running at 2.1 GHz and has 16 GB of RAM and a 128 GB SSD. That’s the equivalent of an AWS EC2 Compute optimized c7g.2xlarge instance which costs about 0.289 USD/hour which comes to $200/month (approx).
Sidenote: I know its not apple to apple comparison between a hardware device and a cloud instance, but for my intended purposes, it totally works.
OS
I used to have this as an alternate desktop system, so it runs Ubuntu 22.04Desktop Version with the default Gnome interface. I removed almost all the desktop software and left only the bare minimum necessary to run the OS and the desktop.
I thought about installing Ubuntu Server edition but couldn’t find a pendrive. So a stripped down desktop OS will have to do.
Software Deployment
Now this I am very particular about.
I want to use Infrastructure as Code tools like Terraform as much as possible. This allows storing all the necessary configuration in a repo, so if and when my HDD fails, I can redeploy them again without having to do each and every one of them by hand again.
I want to have some form of Web UI that can show the running services and resource consumption, if possible
First up is YUNOHost – It is an OS dedicated to self-hosting and supports a huge number of software and has a nice UI to manage them. But, the ones I want to host (Misskey) aren’t there and I don’t think storing config as code is an option here.
Next I looked at docker-compose – I am very familiar with it. The config can be stored as files and reused for redeployment. A lot of software are distributed with docker-compose files themselves. But, there is no web UI by default, and I also don’t want to run multiple copies of the same software.[1]
I have some experience with Kubernetes – There are lightweight alternatives like K3S, that might be suitable for a single node system. It fulfills the config-as-code and the Web UI requirements. But, the complexity is a bit daunting and the yaml can get a little unwieldy. And also everything needs to be in a container.
Finally I settled on Nomad – It seemed to have a fine balance.
It can handle docker containers, execute shell scripts, run Java programs..etc.,
The config is stored in JSON like HCL files, which feels better than the YAML
It has a web UI to see running services and resource utilization.
Footnotes
[1] – When software are distributed using docker-compose files, they tend to have all the necessary services defined in them. That usually means, along with the core software they also have other things like a database (Postgres/MariaDB), a web server (Nginx/Apache), a cache (Redis/Memcache)..etc., So, when multiple software are deployed with vendor supplied docker-compose files, it ends up running multiple copies of the same services using up unnecessary CPU and memory.
The author of the post mentions how, he has configured it to be a standalone personal search engine. The workflow is something like this:
Browse the web
Come across an interesting link that you need to bookmark
Add the URL to the YACY Crawler and crawl to the depth=0, which crawls just that page and indexes it.
Next time you need it, just search for any word that might be present on the page.
This is brilliant, because, I don’t have to spend time putting it the right folder (like in browser bookmark) or tagging it with right keywords (as I do in Notion collections). The full text indexing takes care of this automatically.
But, I do have to spend time adding the URL to the YACY Crawler. The user actions are:
I have to open http://localhost:8090/CrawlStartSite.html
Copy the URL of the page I need to bookmark
Paste it in the Crawling page and start the crawler
Close the Tab.
Now, this is high friction. The mental load saved by not tagging a bookmark is easily eaten away by doing all of the above.
yacy-it
Since I like the YACY functionality so much, I decided I will reduce the friction by writing a Firefox Browser Extension – https://github.com/tecoholic/yacy-it
This extension uses the YACY API to start crawling of the current tab’s URL which I click the extension’s icon next to the address bar.
I listen to podcasts while doing chores like cooking, travelling in public transport, doing dishes…etc., In most cases, I just absorb what I can with the partial attention I provide to the podcast. Recently I thought, I would listen to some of them with a bit more attention, like a lecture and take some notes. I learnt a lot in this one from how EV range anxiety is a non-problem to wineries hedge their quality of wine my mixing grapes from different fields.
Introduction
This one is a conversation between Bloomberg Opinion columnist Barry Ritholtz speaks and Darren Palmer, Ford Motor Co.’s vice president for electric vehicle programs. They take about Darren Palmer’s professional journey in Ford and Ford’s electric vehicle lineup and the future of Ford and Electric vehicles.
Ford Electric Vehicles
11 Billion starting investment
50 billion in current investment
use lessons from startups for velocity of execution
travelled to EV rich countries like Norway to China to learn
Interesting case where an EV user declined 100% refund of the EV vehicle and a BMW car to get rid of the EV and switch to petrol car, because he was holding the future and he doesn’t want to go back
focus on millennial market + Mustang brand
lack of Operating System is what was the limiting factor once the design was completed
using web technologies for creating the interface provided the team with great velocity
UI was hosted by a developer sitting at home, which was live updated during a test run based on customer complaint
from the first day, social media is being watched and feedback followed up
Team Edison – has a very flat structure
Ask what they want and move out of their way
fast track approvals and let them do their jobs
Converting Petrol Heads
Mustang club wasn’t comfortable and said they won’t be endorsing the EV Mustang
end of the launch presidents of both the Mustang clubs had purchased multiple vehicles
realisation – EV provides complementary experience with Petrol vehicles
petrol heads are not petrol heads, but performance heads and electric vehicles can deliver better performance
EV Mustang has such a performance that the only thing needed to be done to convert a person into EV is just getting them into the EV vehicle
tests for the vehicles are no longer done with humans because the acceleration limits are too high
torture tests for Ford vehicles on YouTube
E Transit – Vans
Focus on commercial customers
Payback starts from day 1
running costs are about half
extra mileage is limited because of predictability of routes – so EV mileage anxiety is not an issue
trips are planned and executed with right charging window
only 10% of our market
everyday seeing new use-cases in the commercial sector
Use-case #1: French Winery
wineries collect grapes from different parcels of land and mix them to get an average better wine (if 1 of 3 is bad), they still get a decent wine because of the 2 good parcels
but they don’t know if they have had 2 of 3 bad until a year later when they pull samples from the vats
a winery wanted to get the best quality and decided to use 1 vat per parcel, so at t
vat sizes are big and restriction on building above ground, so winery built the vats under ground by a mountain side
used the diesel vehicles for transportation
converted entire fleet to the electrical after seeing electrical performance
talks to American group of wine makers
now there is a huge demand from the wineries for electrical vehicles
USE-CASE #2: Mobile kitchens
popup kitchens with electric equipment
uses the battery to drive to people’s homes, plug-in and start cooking
battery operated electrical vehicles can use the battery to power the kitchen
BlueOval Charging Network
have the resources to setup independent network
but poor value for customers with each manufacturer setting up their own networks – so created a coalition
there are regional networks
remote monitoring of all stations
payment systems, terminals, ..etc all have to play along
they have instrumented vehicles, roaming the network, just to test the charging stations
problems identified are communicates to the CEOs of the stations of the network
problematic stations can be removed from the network if the quality problems aren’t addressed
Long charge times
perception is very different
charge in iPhone is bad compared to a flip phone, still no-one wants to switch back to a flip phone after using an iphone
the process of going to get petrol is obsolete
it actually takes 30 seconds to charge the car – because all you do is just plugin
daily charge is almost never conscious – go home, plugin and walk away, its charged and ready to go when you come back to it again
tech to charge faster is still developing
but it makes less difference than we think because the human element plays a very big role in when/how we charge
with 300 mile cars (current range of Ford EVs), it’s not actually a requirement
users will take a break after driving for a couple of hours (~200 miles), pit stops are more than necessary to replenish the charge
large miles like 800-1000 miles
Recycling and reusablity
materials are really in demand
if they don’t have access to minerals for batteries now, they are going to be in trouble
Blue City (Blue Ocean City? Blue Oval City??) – vertical integrated city for battery integration
collection of leftover and recycling to be more efficient in production
Buttons in the Cars
hardware switches/buttons are difficult to modify once installed
software provides the ability to change and modify
context level buttons – adaptable interface based on the context
parking camera buttons are not needed at 60 miles/hr – UI can hide them
smart vehicles can remember the way you park, so it will auto launch camera when on parking mode and can remember which camera is more frequently used and launch it automatically
smart UI with sensible human overrides
we think we need a button until we are presented with a better experience
no cycling around the cameras pressing the same button again and again
Customer education
basic problems because customers completely ignore the instructions
they just buy the car and use it without any research
so gamification kind of notifications to teach customers about nuances of an EV