Selecting elements from a list that satisfy a condition
selected = []
for i in items:
if condition:
selected.append(i)
# Simpler version using List comprehension
selected = [i for i in items if condition]
Selecting elements from a list that satisfy a condition
selected = []
for i in items:
if condition:
selected.append(i)
# Simpler version using List comprehension
selected = [i for i in items if condition]
I am currently working on a project called Peer Feedback, where we are trying to build a nice peer feedback system for college students. We use Canvas Learning Management System (CanvasLMS) API as the data source for our application. All data about the students, courses, assignments, submissions are all fetched from CanvasLMS. The application is written in Python Flask.
We are mostly getting data from API, realying it to frontend or storing it in the DB. So most of our testing is just mocking network calls and asserting response codes. There are only a few functions that contain original logic. So our test suite is focused on those functions and endpoints for the most part.
We recently ran into a situation where we needed to test something that involved the fetching and filtering data from API and retriving data from DB based on the result.
The problem we ran into is, we can’t test the function without first initalizing the database. The code we had for initializing the CanvaLMS used the Faker library, which provides nice fake data to create real world feel for us. But it came with its own set of problems:
While we had the feel of testing realworld information, it came with real world problems. For e.g., I cannot log in as a user without first looking up the username in the output generated during initialization. So I had to maintian a postit on my desktop, use search functionality to find the user I want to test and copy his email and login with it.
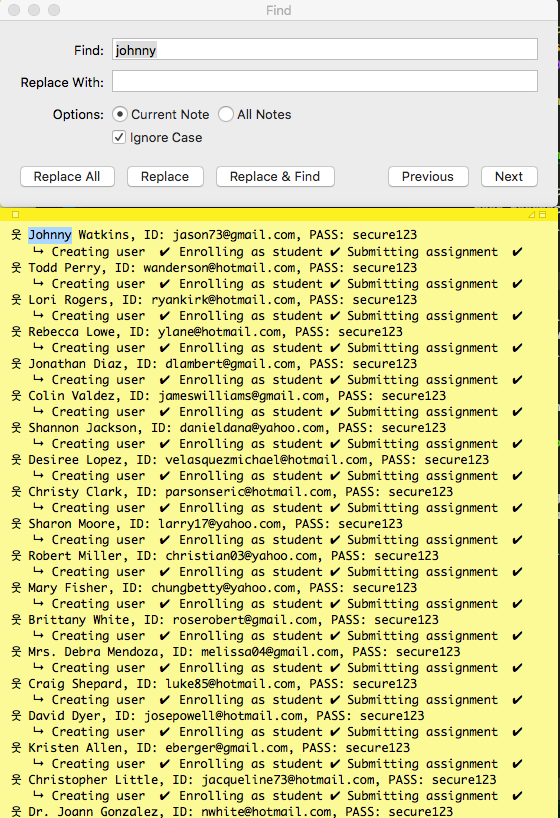
When we write our tests, there is no assurity that we could reference a particular user in the test with the id and expect the parameters like email or user name to match. With the test data being generated with different fake data, any referencing or associaation of values held true only for that cycle. For e.g, a function called get_user_by_email couldn’t be tested because we didn’t know what to expect in the resulting user object.
To compensate for the inconsistency in the data across cycles, we increased the complexity of the test suite, we saved test data in JSON files and used it for validation. It became a multi step process and almost an application on its own. For e.g, the get_user_by_email function would first initialize the DB, then read a json file containing the test data and get a user with email and validate the function, then find the user without an email and validate it throws the right error, find the user with a malformed email… you get the idea. The test function itself not had enough logic warranting a test of test suites.
With the realworld like data came the realworld problems. The emails generated by faker are not really fake. There is a high chance a number of them are used by real people. So guess what would have happened when we decided to test our email program 🙂
We finally are switching to a more sensible test data for our testing. We are dropping the faker data for user generation, and shifiting to the sequencial user generation system with usernames user001 and emails [email protected]. This solves the above mentioned issues:
user001 would have the email [email protected] and that these associations will be consistent across test cycles.userXXX template, reducing complexity of the test suite.Faker provided us with data which helped us test a number of things in the frontend, like the different length in names, multi part names, unique names for testing filtering and searching etc., while also added a set of problems that makes our work difficult and slow.
Our solution to having a sensible dataset for testing is plain numerically sequenced dataset.
Using the generic name tags like user was still causing friction as we have multiple roles like teacher, TAs, students …etc., So I improved it further by creating users like student0000, ta000, `teacher00“.
# Setting a value based on condition
if condition:
choice = "Head"
else:
choice = "Tail"
# Single line Version
choice = "Head" if condition else "Tail"
When you have to check for the presence of a value in a list and set a flag based on it, we can avoid typical:
set default => check => update
routine in Python and condense it to a single line like this.
orders = ['pizza', 'coke', 'fries']
order_book = {}
# Setting an yes or no flag in another dictionary or object
order_book['pizza'] = False
if 'pizza' in orders:
order_book['pizza'] = True
# Simpler Version
order_book['pizza'] = 'pizza' in orders
Extended Assignment Operators – we use them all the time as shorthands for assigning values.
Lets see how this works when using multiple identifiers (variables) in terms of simple data like a number.
>>> a = 5 >>> b = a >>> b += 3 >>> print(a) 5 >>> print(b) # only the value of b is changed even though we have assigned a to b 8 >>> b = b+4 # the long form assignment also doesn't affect the original a >>> print(b) 12 >>> print(a) 5
Let us apply a similar set of operations on list
>>> a = [1,2,3] >>> b = a >>> b += [4,5] >>> print(a) # surprise! - changing the value of b also affect the value of a [1, 2, 3, 4, 5] >>> print(b) [1, 2, 3, 4, 5] >>> b = b+[6,7] >>> print(b) [1, 2, 3, 4, 5, 6, 7] >>> print(a) [1, 2, 3, 4, 5] # surprise again !! - but assigning a new value to b doesn't
Now the question is, why does the value of a change when adding elements to b?
And furthermore why doesn’t it change when we do it using the long form?
The answer is: Extended assignment operators act differently on mutable and immutable values.
So when we say b += [4,5] we are basically saying add 4 and 5 to the list b, but when we say
b = b + [6,7], we are saying “take the list b, add 6, 7 to it and create a new list from it, then assign it to the identifier b”.
This subtle difference will come to bite us when we least expect it. So be aware and take precautions 🙂
A class has N number of students. When the students submit an assignment, they are assigned K peers to review their assignments and provide feedback such that 0 < K = N
Input: N=3, K=1
Output:
{
0: [1],
1: [2],
2: [0]
}
Input: N=3, K=2
{
0: [1,2],
1: [2,0],
2: [0,1]
}
def generate_peer_pairs(N, K):
"""A function that provides unique peers for reviewing.
The generated matches follow the following rules:
1. The no.of reviews/rounds of review is less than total no.of users.
2. The user won't be reviewing his/her own work
3. All the reviewers assigned would be unique.
4. Each user will have equal no.of reviews to give and receive.
:param N: Total no.of student for whom the matching is to be done.
:param K: The no.of reviews each student is supposed to receive.
:returns: a dictionary of graders and their peers { grader_id: [peer_1, peer_2, ...]}
"""
if K >= N:
return False
available_offsets = list(range(1, N))
offsets = []
while len(offsets) < rounds:
offset = random.choice(available_offsets)
offsets.append(offset)
available_offsets.remove(offset)
students = list(range(N))
random.shuffle(students)
allocations = {}
for idx, student in enumerate(students):
allocations[student] = [students[(idx + offset) % N] for offset in offsets])
return allocations
The problem is an interesting one. I started out with the idea that the peers should be arranged in a random way and wrote an algorithm by selecting a random recipient while looping over each grader. It was completely non-roboust and failed to make the right pairs more times that it worked.
The solution if you had noticed, is completely a position shifting algorithm. What appears a non-repeating random order for the grader and the recipient is not really that random.
I have been working on the problems in Codility to get better at the algorithms and also to expand the way I solve problems in general. One common thing I notice with using Python as the language is that, sometimes the solutions are so simple I wonder if I learnt anything at all.
Take for example, this challenge called GenomicRangeQuery which aims to teach the application of Prefix sums in problem solving. Here is the solution which gets the perfect score of 100% for both accuracy and complexity.
def solution(S, P, Q):
mins = []
for i in range(0, len(P)):
start = P[i]
end = Q[i]+1
sub = S[start:end]
if 'A' in sub:
mins.append(1)
elif 'C' in sub:
mins.append(2)
elif 'G' in sub:
mins.append(3)
else:
mins.append(4)
return mins
The solution felt like cheating and also, I wasn’t sure of the complexity of in keyword magic of Python. I searched for a solution in a low level language to understand better. Here is it in Java. Reproducing for quick comparison.
public static int[] genome(String S, int[] P, int[] Q) {
int len = S.length();
int[][] arr = new int[len][4];
int[] result = new int[P.length];
for(int i = 0; i < len; i++){
char c = S.charAt(i);
if(c == 'A') arr[i][0] = 1;
if(c == 'C') arr[i][1] = 1;
if(c == 'G') arr[i][2] = 1;
if(c == 'T') arr[i][3] = 1;
}
// compute prefixes
for(int i = 1; i < len; i++){
for(int j = 0; j < 4; j++){
arr[i][j] += arr[i-1][j];
}
}
for(int i = 0; i < P.length; i++){
int x = P[i];
int y = Q[i];
for(int a = 0; a < 4; a++){
int sub = 0;
if(x-1 >= 0) sub = arr[x-1][a];
if(arr[y][a] - sub > 0){
result[i] = a+1;
break;
}
}
}
return result;
}
Needless to say, the solution is beautiful and as intended (teaches the application of prefix sums).
The difference in the complexity of the two solutions showcases the power and simplicity of Python.
So what am I doing with Python? I am writing simpler code definitely. It is good. I am also worried that I might not be learning a number of techniques that will help in the long run.
As a part of my work, I needed a console like viewer in a web application (like the one used in travis.ci). The frontend is simply Bootstrap 3 and some jQuery JavaScript. I have written a rudimentary one using Bootstrap’s Panel and List Groups and using the helper classes to style them. But the application has grown and it is time we got a really good log viewer.
React with JSX syntax, the ability to just drop the the library and use it for only selective parts of the app seemed just right. After trying out the tic-tac-toe tutorial, I ventured to setup it for our project.
JSX is not plain native Javascript. Even-though I could include the React and ReactDOM libraries using the script tags, I have to setup a node.js based environment to compile the JSX into JS.
The Flask app has a typical structure as show below
-- project/
|-- flask_app/
| |-- static/
| | |-- js/
| | |-- css/
| | |-- images/
| |-- tempaltes/
| |-- __init__.py
| |-- application.py
| |-- views.py
...
|-- run.py
|-- .gitgnore
|-- README
React’s Adding React to an Existing Application lists three requirements – a package manager, a bundler and a compiler. I used npm for package manager, Webpack for bundler and Babel for the compiler. Here are the steps for the setup:
package.json file using npm init inside project directory.ui insdie the project to hold the React JSX filesreact, react-dom using npm install --savewebpack, babel-core, babel-loader, babel-preset-env, babel-preset-react using npm install --save-dev"build": "webpack --config webpack.config.js" to the scripts block of package.json.babelrc with a single line {"presets": ["react", "env"]}webpack.config.js with the contents
const path = require('path');
module.exports = {
entry: './ui/logger.js', // logger.js is where I plan to write the JSX code
output: {
path: path.resolve(__dirname, 'flask_app/static/js/'),
filename: "logger.js"
},
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
}
}
Here is what I have done so far:
package.json to manage things like requirements for the JS files, run npm commands, …etc. I guess this is like the setup.py of Python world.ui/logger.js file and compile it using Babel and put it the Flask app’s static/js/ folder so that it can be used in the Jinja templates using url_for('static', filename='logger.js')npm run build would run webpack to compile and put the file in static folder.After adding everything, this is how the project looks
-- project/
|-- flask_app/
| |-- static/
| | |-- js/
...
|-- run.py
|-- .gitgnore
|-- README
|-- node_modules/
|-- ui/
| |-- logger.js
|-- .babelrc
|-- webpack.config.js
|-- package.json
With the above setup, I am good to go. All I need to do is add a script tag with src pointed to the logger.js. With everything setup,
ui/logger.jsnpm run build (the file compiled and was put in the static/js/ folder)python run.pyEverything worked as expected.
Now I changed the code in ui/logger.js > ran npm run build > reloaded the page in browser. Nothing changed. Now we have a problem. It’s the browser caching the output static/js/logger.js file.
While Caching is good from a client’s point of view, it is a little tricky in a development environment. If we were building a full blown React app using the react-cli, we won’t have this issue as the react-scripts would watch the file changes and reload the browser for us. In the current setup using Flask’s development server, however, we need to take care of it ourselves. Webpack to the rescue.
I followed Webpack’s Caching guide and applied everything suggested. Now the webpack.config.js looks like this:
const webpack = require('webpack');
const path = require('path');
const CleanWebpackPlugin = require('clean-webpack-plugin');
module.exports = {
entry: {
main: './ui/logger.js',
vendor: [
'react', 'react-dom'
]
},
output: {
path: path.resolve(__dirname, 'flask_app/static/build'),
filename: "[name].[chunkhash].js"
},
module: {
rules: [
{ test: /\.js$/, exclude: /node_modules/, loader: "babel-loader" }
]
},
plugins: [
new CleanWebpackPlugin(['flask_app/static/build']),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor'
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime'
}),
]
}
This is what the updated webpack config does:
– instead of saving the generated Javascript as a single file called logger.js it splits the output into three files named
* main.[chunkhash].js which contains the compiled ui/logger.js
* vendor.[chunkhash].js which contains the libraries listed in entry.vendor
* runtime.[chunkhash].js which contains the Webpack’s runtime logic to load the files generated
Note: the chuckhash is a value that webpack substitutes when generating the files. This changes with the changes in entry files. So we have a different filename in the output with every build, thus avoiding the caching issue.
CleanWebpackPlugin removes all the files in the output directory before generating new files so we don’t have outdated files like main.hash1.js, main.hash2.js.. etc.,static/js folder has other files like bootstrap, jquery ..etc., So the output.path is set to a new directory static/build, to prevent the Clean Webpack plugin from deleting them.With the above config, we will have a different filename everytime we build using npm run build. Now the file cached by the web browser is not used as the new filename is different from the old one.
But how do we use the latest filenames in the “ tag in the Jinja templates?
There is a plugin to solve this issue called Flask-Webpack, but I felt it too be an overkill.
Add the following context processor to the Flask app:
@app.context_processor
def hash_processor():
def hashed_url(filepath):
directory, filename = filepath.rsplit('/')
name, extension = filename.rsplit(".")
folder = os.path.join(app.root_path, 'static', directory)
files = os.listdir(folder)
for f in files:
regex = name+"\.[a-z0-9]+\."+extension
if re.match(regex, f):
return os.path.join('/static', directory, f)
return os.path.join('/static', filepath)
return dict(hashed_url=hashed_url)
This provides a function called hashed_url which looks for the file and returns its hashed form. Now we can add the files using script tags as below:
<scrip.t src="{{ hashed_url('build/runtime.js')></script>
<scrip.t src="{{ hashed_url('build/vendor.js')></script>
<scrip.t src="{{ hashed_url('build/main.js')></script>
The hashed_url would match the filename passed to it with the the files in the directory and returns the hashed form. For e.g., hashed_url("build/main.js") returns /static/build/main.16f45d183a4c0f0b1b37.jss
The whole process of setting this up took multiple hours of research and testing. I could have used one of the available boilerplates to set this up, but I now have it in the form I want it and I understand what the different parts mean and do. It lets me use React for small components as required and grow as the project grows. It also creates no disruption in the workflow of other developers. Happy coding time ahead 🙂
Unit testing a big python application comes with its own set of worries which includes mocking calls to parts of code which we will test somewhere else.
Let us say I have a **utils.py** (every project has one anyways)
# utils.py
def word_length(name):
# here it is a trivial function
# assume that this is a costly network/DB call
return len(name)
And I have another module which uses word_length using the from module import function syntax.
# user.py
from project.utils import word_length
def calculate(name):
length = word_length(name)
return length
Now I want to unit test all the functions in **user.py** and since I am going to test just the user module and want to avoid costly calls made by my utils module I am going to mock out calls to `word_length` using Python mock library.
# test_user.py
from project.user import calculate
from mock import patch
@patch('project.utils.word_length')
def test_calculate(mock_length):
mock_length.return_value = 10
assert calculate('hello') == 5
One would expect this assertion to fail because we have mocked out the word_length to return 10. But this passes and our mock is not working. Why? Because **NAMESPACE**. Here we have patched the function in the namespace utils. But we have imported the function to the user.py namespace by using `from module import function`. So we need to patch the function in the user namespace where it is used and not in the utils where it is defined. So change the line
@patch('project.utils.word_length')
# to
@patch('project.user.word_length')
But what if we have used simply like
# user.py
import utils
def calculate(name):
length = utils.word_length(name)
return length
This time we can straight away use the @patch('project.utils.word_length') as we are importing the entire module and namespace remains as such.
I was woken up today with the following question:
[python]
def foo(x=[]):
x.append(1)
return x
>>> foo()
>>> foo()
[/python]
What could be the output? The answer is
[1]
[1, 1]
I was stupefied for a minute before I started DuckDuckGo-ing Python default arguments, Python garbage collection, Python pitfalls..etc.,
These links helped me understand mutable objects’ memory management.
Deadly Bloody Serious – Default Argument Blunders
Udacity Wiki – Common Python Pitfalls
Digi Wiki – Python Garbage Collection
