This is a follow up to the previous article: Simplifying JSON parsing in Flask routes using decorators
In the previous article we focused on simplifying the JSON parsing using decorators. The aim was to not repeat the same logic in every route adhering to the DRY principle. I will focus on what goes on inside the decorator in this article.
I ended the last article with the following decorator (kindly see the implementation of @required_params in the previous article)
@route(...)
@required_params({"name": str, "age": int, "married": bool})
def ...
where we pass the incoming parameters and their data types and perform their type validation.
Using an external library for validation
The decorator implemented above is suitable for simple use cases. Now, consider the following advanced use cases
- What if we need more complex validations like Email or Date validation?
- What if we need to restrict a field to certain values? Say
roleshould be restricted to (teacher,student,admin)? - What if need to have custom error messages for each field?
- What if the value of a parameter is an object with its own set of validation rules?
Solution for neither one of them is going to be trivial enough to be implemented in a single & simple decorator function. This is when the external libraries come to our rescue. Libraries like jsonschema, schematics, Marshmallow ..etc., not only provide functionality, they would also bring more clarity to the codebase, provide modularity and improve the readability.
Note: If you are already using a serialisation library like marshmallow in your project to handle your database Models, you probably knew all this. If you don’t use a serialisation library in your project and instead have something like to_json() or to_dict() function in your models, then you SHOULD consider removing those functions and use a serialisation library.
Example application
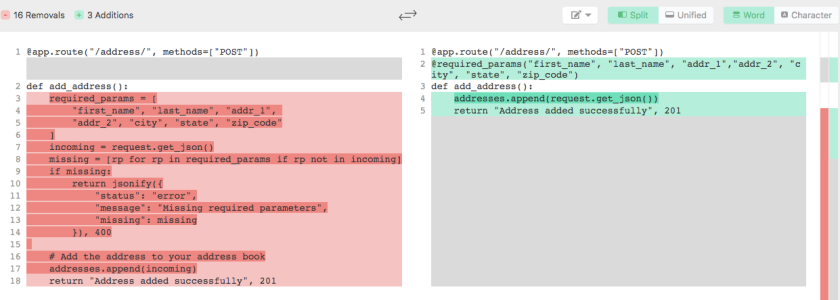
Let me layout an example use case which we use to explore this. Here we have a simple app that has two routes which accepts JSON payload. The expected JSON data is described in the decorator @required_params(...) and the validation is carried out inside the decorator function.
| from flask import Flask, request, jsonify | |
| from functools import wraps | |
| app = Flask(__name__) | |
| users = [] | |
| def required_params(required): | |
| def decorator(fn): | |
| @wraps(fn) | |
| def wrapper(*args, **kwargs): | |
| _json = request.get_json() | |
| missing = [r for r in required.keys() | |
| if r not in _json] | |
| if missing: | |
| response = { | |
| "status": "error", | |
| "message": "Request JSON is missing some required params", | |
| "missing": missing | |
| } | |
| return jsonify(response), 400 | |
| wrong_types = [r for r in required.keys() | |
| if not isinstance(_json[r], required[r])] | |
| if wrong_types: | |
| response = { | |
| "status": "error", | |
| "message": "Data types in the request JSON doesn't match the required format", | |
| "param_types": {k: str(v) for k, v in required.items()} | |
| } | |
| return jsonify(response), 400 | |
| return fn(*args, **kwargs) | |
| return wrapper | |
| return decorator | |
| @app.route('/') | |
| def hello_world(): | |
| return 'Hello World!' | |
| @app.route("/user/", methods=["POST"]) | |
| @required_params({"first_name": str, "last_name": str, "age": int, "married": bool}) | |
| def add_user(): | |
| # here a simple list is used in place of a DB | |
| users.append(request.get_json()) | |
| return "OK", 201 | |
| if __name__ == '__main__': | |
| app.run() |
Requests and responses
Now let us sent an actual request to this application.

Now that is really nice, we have got a “201 Created” response. Let us now try with a wrong input. I am setting the married field to twice instead of true or false, the expected boolean values.

That returns a 400 Bad request as expected. The decorator has tried validating the types of the input and has found that one of the values is not in the expected format. But the error message itself is kind of crude:
- It doesn’t actually tell us which parameter is wrong. In a complex object this might lead to wasting a lot of time jumping between the docs and the input to guess and find the wrong parameter.
- The data types are represented as Python class types like
class 'int'. While this might convey the intended meaning, it is still far better to say something decent likeintegerinstead.
Using Marshmallow for validation
Using the marshmallow we can define the schema of our expected JSON.
from marshmallow import Schema, fields, ValidationError
class UserSchema(Schema):
first_name = fields.String(required=True)
last_name = fields.String(required=True)
age = fields.Integer(required=True)
married = fields.Boolean(required=True)
Now that the marshmallow will take care of the validation, we can update our decorator too:
def required_params(schema):
def decorator(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
try:
schema.load(request.get_json())
except ValidationError as err:
error = {
"status": "error",
"messages": err.messages
}
return jsonify(error), 400
return fn(*args, **kwargs)
return wrapper
return decorator
And finally we pass an object of the UserSchema instead of a list of params in the decorator:
@app.route("/user/", methods=["POST"])
@required_params(UserSchema(strict=True))
def add_user():
# here a simple list is used in place of a DB
users.append(request.get_json())
return "OK", 201
Note: I have passed the strict=True so that Marshmallow will raise a ValidationError. By default marshmallow 2 doesn’t raise an error, however, it should be happening in version 3. Check your version to see if the strict parameter is necessary.
With the app updated, now let us send a request and test it.

Good. We get the “not a boolean” validation error. Now what if we have multiple errors?

Sweet, we get parameter specific error messages even for multiple errors. If you remember our original implementation, only one error could be returned at a time because the first exception would return a response. Using the library provides a good upgrade from that.
By defining multiple schemas for the various data models that we expect as an input, we could perform complex validations independent of our view function. This gives us clean view functions that handle just the business logic.
Conclusion
This post only exposes the basic implementation of using the libraries and simplifying parsing and validation of incoming JSON. The marshmallow library offers a lot more like: complex validators like Email and Date, parsing subset of a schema by using only, custom validators (age between 30-35 for example), loading the data directly into SQLAlchemy models (check out Flask-marshmallow)..etc., These can really make app development easier, safer and faster.
Schematic is another library offering similar functionalities that focuses on ORM integration.